The data that
makes AI
actually work.
Every AI model is only as capable as the data it learns from. Vindhya builds, labels, and validates that data — across text, images, audio, and regional languages — so your models learn from the real world, not a clean but incomplete version of it.
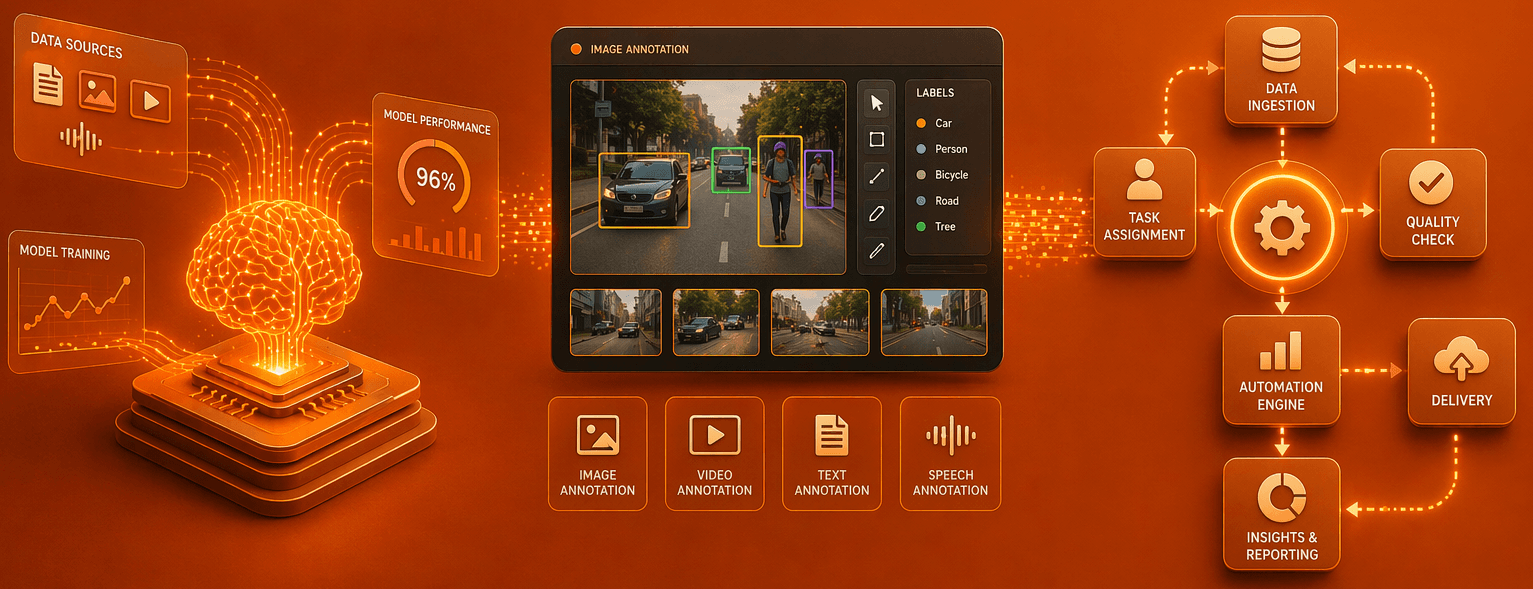
Three services.
One purpose: better AI.
AI models learn from data. The quality, diversity, and accuracy of that data directly determines how well the model performs in the real world. Building good AI training data is not a technology problem — it is a human operations problem. It requires people who can generate realistic conversations, label content accurately at scale, and review outputs against quality standards without compromise.
Vindhya's AI Data Services bring together three distinct capabilities that cover the full lifecycle of preparing data for AI — from generating raw training data and annotating existing datasets, to validating that the data entering your model is clean, accurate, and safe.
These three services are related but distinct. You may need one, two, or all three depending on where your AI project is and what your models need. The right starting point depends on what data you already have and what your models are trying to learn.
Multilingual Data Collection
When you need new training data created from scratch — structured human conversations, image-prompted recordings, or simulation scenarios in regional languages. You don't have the data yet. We build it.
Text, Image & Audio Annotation
When you have raw data — documents, images, recordings — and need it labelled so your AI can learn from it. We tag, classify, segment, and transcribe at scale across any domain.
Data Quality Assurance
When you have a dataset — generated or annotated — and need a human review layer before it enters your model. We check accuracy, consistency, safety, and completeness against your quality standards.
What each
one covers.
Each service is a standalone capability that can be engaged independently — or combined as a full AI data pipeline. Click any service to explore the dedicated page with full details, capabilities, and case studies.
Multilingual Data Collection & Generation
Real human conversations, image-prompted recordings, and sales simulations across 13+ Indian languages — creating the raw training data AI models need to understand how India speaks.
Conversational Voice Collection
Natural 5–10 minute conversations across 13+ Indian languages. Free-flowing, unscripted, with real accents and dialects from diverse participants.
Image-Prompted Speech Recording
Participants describe visual images naturally in their regional language — producing context-rich speech data for multimodal AI training.
Sales Call Simulation
Trained agents simulate real outbound sales conversations — generating objection handling, intent signals, and pitch data for sales AI models.
Text, Image & Audio Annotation
Precise labelling of existing datasets — entity tagging, sentiment classification, bounding boxes, image segmentation, audio transcription and tagging — across any domain and scale.
Text Annotation
Named entity recognition, sentiment tagging, intent classification, POS tagging, and document categorisation for NLP and LLM training.
Image Annotation
Bounding boxes, polygon segmentation, keypoint labelling, and object classification for computer vision, autonomous systems, and visual AI.
Audio Annotation
Transcription, speaker diarisation, emotion tagging, dialect identification, and timestamp labelling for speech and voice AI models.
Human QA for AI Datasets
Trained human reviewers validate datasets against defined quality checkpoints — ensuring accuracy, consistency, and safety before data enters model training pipelines.
Audio Quality Validation
Every recording reviewed for language accuracy, dialect match, demographic consistency, audio clarity, natural tone, and safety compliance.
Annotation Accuracy Review
Second-pass human review of labelled data — checking for consistency, correctness, and edge cases that automated checks miss.
Dataset Safety Filtering
Identifying and removing abusive, biased, or inappropriate content before it enters training pipelines — protecting model behaviour downstream.
Find the right
starting point.
The three services are related but serve different needs. Use this guide to understand which one fits your current AI project stage — and whether you need one, two, or all three working together.
Flexible models
for every stage.
Whether you need a one-off data generation project, an ongoing annotation operation, or a continuous QA layer running alongside your training pipeline — Vindhya's engagement model adapts to where you are.
Project-Based Engagement
A defined scope, timeline, and deliverable — ideal for one-time data generation, a batch annotation project, or a dataset validation exercise. Fast to start, clean to close.
Ongoing Operations Partnership
A continuous operation running alongside your AI development cycle — generating, labelling, and validating data on a rolling basis as your models evolve and your training needs grow.
Full Pipeline Partnership
All three services working together — data generation feeding annotation, annotation feeding validation, validation feeding your model. One partner, one SLA, full visibility across the chain.
Tell us what your AI
model needs to learn.
We'll identify which service — or combination of services — fits your project stage, and show you how quickly we can have data flowing into your training pipeline.